
Clustering과 Classification(분류)은 굉장히 비슷한 개념이다. 하지만 Clustering은 비지도학습(Unsupervised)으로, 정답이 없는 데이터들을 비슷한 것 끼리 묶을 때 사용한다. 그와 반대로 Classification(분류)은 정답이 있는 데이터들을 사용하므로 지도학습(Supervised)이다.
클러스터링은
①군집 간 분산(inter-cluster variance) 최대화
②군집 내 분산(inner-cluster variance) 최소화
를 목표로 둔다.
- K- means

K-means의 K는 클러스터 수를 의미한다. 위의 예는 K가 2인 경우이다. 군집의 무게중심(빨간색 사각형)을 랜덤으로 초기화한다. 그 후 모든 점들(파란색 점들)의 가장 가까운 무게중심을 기준으로 클러스터링한다 (E스텝) . 그리고 클러스터의 무게중심을 업데이트한다(M스텝).
이렇게 E스텝과 M스텝을 반복하며 최종적으로 결과가 바뀌지 않거나(=해가 수렴), 사용자가 정한 반복수를 채우게 되면 학습을 끝내는 것을 K-means라고 한다.
하지만 K-means는 초기값 위치에 따라 원하는 결과가 나오지 않을 수 있고 클러스터의 밀도나 크기가 다를 경우 원하는 결과가 나오지 않을 수 있으며 데이터의 분포가 특이한 경우에도 잘 적용되지 않는다.
- KNN (K-Nearest Neighbors)
KNN은 Classification이다. 새로운 데이터가 주어졌을 때 기존 데이터 가운데 가장 가까운 K개 이웃의 정보로 새로운 데이터를 예측하는 방법론으로 지도학습(Supervised)이다. 레이지(Lazy)모델이라고도 불리는데 딱히 학습할만한 것이 없기 때문이다.


KNN과 K-mean은 위와 같은 공통점과 차이점이 있다.
- GMM (Gaussian Mixture Model)
GMM은 전체 데이터의 확률분포가 여러개의 정규분포의 조합으로 이루어져 있다고 가정하고 각 분포에 속할 확률이 높은 데이터끼리 클러스터링 하는 방법이다. GMM은 K-means등의 클러스터링 알고리즘으로 잘 묶을수 없었던 아래 데이터에서도 잘 작동한다.
- Hierarchical Clustering (계층적 군집화)
Hierarchical Clustering은 계층적 트리 모형을 이용해 개별 개체들을 순차적, 계층적으로 유사한 개체 내지 그룹과 통합하여 군집화를 수행하는 알고리즘이다. Hierarchical Clustering은 클러스터의 수를 사전에 정하지 않아도 학습 수행가능하다.
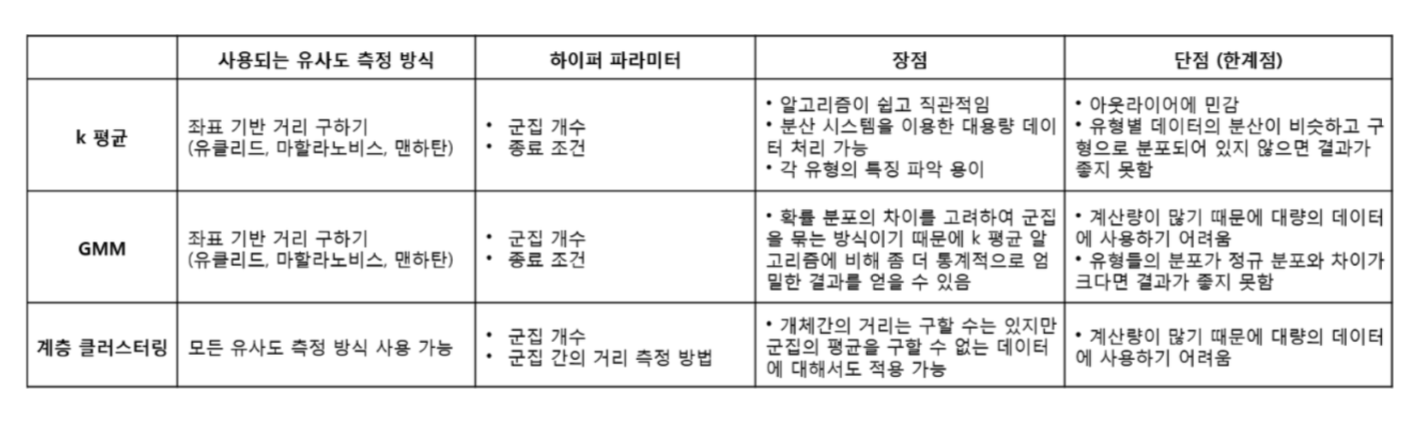
정리
'공부 > 인공지능' 카테고리의 다른 글
| 인공지능 정리8(항등함수, Softmax함수) (0) | 2023.12.10 |
|---|---|
| 인공지능 정리7(Perceptron(퍼셉트론), Sigmoid, ReLU) (1) | 2023.12.10 |
| 인공지능 정리5(Classification(분류)) (0) | 2023.12.10 |
| 인공지능 정리4(회귀(Regression)) (0) | 2023.12.10 |
| 인공지능 정리3(머신러닝 종류) (1) | 2023.12.10 |